


To understand a terminology it is important to understand its history, coding scheme, content model, the intended use cases and editorial policy. In myprevious post, I reviewed the origin of ICD-10. In this post I am going to spend some time talking about the ICD coding scheme and, to be honest, rant a little about structured coding schemes in general.
A coding scheme is the method that is used to assign an identifier to the terms in a terminology. In the history of our industry coding schemes have been important and in some cases iconic. Not sure what I mean? I am sure at least some of you reading this post can look at the following list of codes and identify the source of each on sight. In fact, there are likely some of you that can tell me what the term is for a few of those codes.
1. 55454-3
2. 250.02
3. E11.9
4. 55289-211-60
5. 3E013VG
6. 1-800-783-3637
(Let me know if you get them all – no cheating – answers at the end of the post)
The fact that these codes are recognizable is not an accident. In some cases it is just an iconic pattern and in others it is all part of the logic used to create them. This is because all but one of the above codes is something called a meaningful, or structured, code.
As people we do not typically communicate with codes. Codes are something we created so computers could better cope with the ambiguities of human language and conception. So the target audience for codes is computers, or more appropriately, software. The only reason we need to work with codes is so we can pick the right codes to properly convey information to our silicone-based counterparts. Historically our ability to interface with software has been, for lack of a better word, rustic.
In many cases this required some of us (the lucky ones?) to learn the language of codes so we could speak directly to the software. The problem is, our brains are not typically wired for codes.
Magic Number Seven
In studies conducted during the 1950s it was shown that the capacity of a typical person’s working memory is seven things. This led to what has been dubbed the “magic number seven” by psychologists.
On May 4, 1955 (60 years ago to the day – next Monday), psychologist George A. Miller wrote afascinating paper on the topicthat begins with a great paragraph about the number seven:

“My problem is that I have been persecuted by an integer. For seven years thisnumber hasfollowed me around, has intruded in my most private data, and has每一页攻击我的大多数公共周素卿rnals. This number assumes a variety of disguises, being sometimes a little larger and sometimes a little smaller than usual, but never changing so much as to be unrecognizable. The persistence with which this number plagues me is far more than a random accident. There is, to quote a famous senator, a design behind it, some pattern governing its appearances. Either there really is something unusual about the number or else I am suffering from delusions of persecution.”
米勒博士参与写作风格和佩普r itself is an enjoyable read, if a bit steep at times. It was being written during a the early days of information theory. In the paper he explores our human limitations with respect to retaining and processing unidimensional information. He also describes coping mechanisms that we employ to expand these limits.
“[The] span of absolute judgment and the span of immediate memory impose severe limitations on the amount of information that we are able to receive, process, and remember. By organizing the stimulus input simultaneously into several dimensions and successively into a sequence of chunks, we manage to break (or at least stretch) this informational bottleneck.”
And concludes with his thoughts on the number seven:
”最后,神奇数字7呢?What about the seven wonders of the world, the seven seas, the seven deadly sins, the seven daughters of Atlas in the Pleiades, the seven ages of man, the seven levels of hell, the seven primary colors, the seven notes of the musical scale, and the seven days of the week? What about the seven-point rating scale, the seven categories for absolute judgment, the seven objects in the span of attention, and the seven digits in the span of immediate memory? For the present I propose to withhold judgment. Perhaps there is something deep and profound behind all these sevens, something just calling out for us to discover it. But I suspect that it is only a pernicious, Pythagorean coincidence.”
(If this was a informatics nerd showdown this is where Dr. Miller would drop the microphone...Respect)
This notion of “chunking” or organizing information into patterns and/or applying some logic to the organization of those bits is a brain hack that allows us to expand beyond our natural limitations.
Structured coding schemes take advantage of this hack by chunking meaningful information into short codes so that we can remember blocks of information and when applicable use logic to determine the rest. This is evident in telephone numbers (3 digit areas code, 3 digit prefix – 4 digit suffix), postal codes (5 digit number), social security number (3 digit code, 2 digit code, 4 digit code) and of course ICD codes.
In fact if you look at the code examples I listed in the “quiz” you can see evidence of this type of mechanism. That’s right…I hacked your brain.
The ICD Scheme
The coding scheme for ICD family has been a logical hierarchy for a while now. From ICD-6 through ICD-9 it has been a numeric three digit root code where the first two digits represented a category and the third digit represented a significant axis, like anatomic location. This base code (referred to as the “rubric”) is followed by a period and then up to two additional digits representing the etiology and sub-classification. In ICD9 they later added the V and E codes into the first position to support external causes, clinical modifiers.
The coding scheme in ICD-10 is still a logical hierarchy, but it has adopted an alphanumeric approach which gave it some room to maneuver. Like its predecessor, it starts with a three byte rubric. In ICD-10 the rubric represents a category. In the international ICD-10 the rubric is a letter followed by two digits. In the 2011 version of ICD-10-CM this was changed to allow the third character to be a digit or a letter, due to the need to expand the rubrics. In the 2014 edition of ICD-10-CM there are 567 codes where the character digit is an ‘A’ and 9 codes where the third character is a B.
The General Structure
In general the rules of the ICD-10-CM scheme are as follows:
- Consists of three to seven characters
- First character is alpha (All letters used except 'U' - 'U' are not invited...)
- Second character is numeric
- Third character can be alpha or numeric
- Decimal placed after the first three characters
- Fourth, fifth, sixth, and seventh digits can be alpha or numeric
Here is a basic picture of a full seven digit ICD-10-CM code:
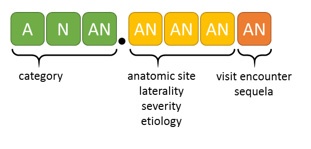
Not all codes include all of the positions and the visit encounter digit is typically used for injury and external cause-related codes.
The Logical Hierarchy
A simple example of the hierarchical nature of the ICD-10-CM structure for a neoplasm code is illustrated below:
| D30 | Benign neoplasm of urinary organs |
| D30.0 | Benign neoplasm ofkidney |
| D30.00 | Benign neoplasm ofunspecified kidney |
| D30.01 | Benign neoplasm ofright kidney |
| D30.02 | Benign neoplasm ofleft kidney |
You will notice that:
- The category of D30 represent the type of neoplasm and the anatomic region (in this case)
- The anatomic location of kidney is the ‘0’ in the fourth position
- Unspecified is the ‘0’ in the fifth position
- Right is the ‘1’ in the fifth position
- Left is the ‘2’ in the fifth position
Neoplasms and diseases tend to follow this simple pattern. But the positions of the relative aspects can vary based on the category. The values used for a given anatomic location or laterality are mostly consistent but that is generally the same as inconsistent so you should not rely on them programmatically.
For an injury code you will notice that the structure is a little more involved:
| M80 | Osteoporosis with current pathological fracture |
| M80.0 | Age-related osteoporosis with current pathological fracture |
| M80.00 | Age-related osteoporosis with current pathological fracture, unspecified site |
| M80.00XA | Age-related osteoporosis with current pathological fracture, unspecified site, initial encounter for fracture |
| M80.00XD | Age-related osteoporosis with current pathological fracture, unspecified site, 随后遭遇骨折智慧h routine healing |
| M80.00XG | Age-related osteoporosis with current pathological fracture, unspecified site, 随后遭遇骨折智慧h delayed healing |
| M80.00XK | Age-related osteoporosis with current pathological fracture, unspecified site, 随后遭遇骨折智慧h nonunion |
| M80.00XP | Age-related osteoporosis with current pathological fracture, unspecified site, 随后遭遇骨折智慧h malunion |
| M80.00XS | Age-related osteoporosis with current pathological fracture, unspecified site, sequela |
The seventh character is sometimes referred to as the extension. For injuries and external causes the codes that are used for the encounter types are:
- A - Initial encounter
- D - Subsequent encounter
- S – Sequelae(a secondary result)
For fractures specifically addition codes are needed to reflect additional fracture-related details:
- A - Initial encounter for closed fracture
- B - Initial encounter for open fracture
- D - Subsequent encounter for fracture with routine healing
- G - Subsequent encounter for fracture with delayed healing
- K - Subsequent encounter for fracture with nonunion
- P - Subsequent encounter for fracture with malunion
- S - Sequelae
The extension always goes in the seventh character. If there is no value for the sixth character, as in the example above, is it filled in with an ‘X’ (like a short cartoon expletive…).
Rule 6! ... There is no… rule 6
In some states is it illegal to borrow your neighbors vacuum cleaner and in others it isn’t. The logical rules of the ICD-10-CM coding scheme are like that. In some sections of the terminology (based on a range of initial alpha characters) the rules for the structure shift around and in some cases the rules within a given neighborhood are violated out right. What this means is that you cannot rely on the "logical" rules. This leads me to ask, why even pretend to have rules? and… when can I get my vacuum cleaner back?
Logical Coding Scheme Rant – as promised
Logical hierarchy coding schemes represent an interesting dichotomy. Like their more expressive cousin, mnemonics, they were born in a time when the population of code systems was limited to a degree that a typical person could use brain hacking to reasonable access them. The problem with using this approach today is that the same structural rigor that allows us to remember a meaningful code imposes limitations on the amount of information that can be represented in that structure.
For example, the first digit of the ICD-10 rubric has exactly 26 possible values (A-Z) and prior to 2015, each initial alpha can have 100 possible values (00-99). That gave us an upper limit of 2600 rubrics. Beyond the rubric this also means that each position in the code has a limit of 10-36 values depending on whether you allow number, letters or both. In the case of ICD-10-CM this limitation created an issue when some of the rubrics ran out of space (like ‘C7-’), which required a decision to be made; should new codes be added into other rubrics where there is space available or break the previously existing rules that said a rubric was a letter followed by two digits? Obviously, they chose the latter. The reason for a meaningful code is that it is predictable and we rely on that predictability in our minds and, for many of us, in our software’s logic. How many systems had a regular expression that expects a letter followed by two digits to recognize or validate an ICD-10-CM rubric?
A logical hierarchy coding scheme also limits how the information can be represented. Specifically as the structure of the code precludes anything other than a mono-hierarchy. Unless you want to be in the business of duplicating codes. This also means that if you want to change the location of a term in the hierarchy you need to change its code. The National Drug Code (NDC) is a good example of this. The first two bytes historically represented the labeler or manufacturer. In the unlikely event that one of these pharma giants purchases another… the meaningful code becomes somewhat less meaningful.
The Donut Conundrum

Structured coding schemes are like donuts, I like them, but they ultimately lead to regret. As an engineer, I am drawn to structured codes like a moth to a flame. It is what I “grew up” with and it is much easier to remember a structured code than a thirty six byte GUID (global unique identifier). However, whenever I succumb to that siren song and create something with the limitation of a central number wheel or a logical structure, it almost always results in a hard choice or rework down the road. Structured coding schemes are the comfort food from our software past that should be removed from the terminology food pyramid.
The Desiderata
In his “desiderata for controlled medical vocabularies”, Dr. James Cimino does an excellent job of explaining why meaningful codes are problematic and suggests instead what he calls a nonsemantic concept identifier. I would go a step further and suggest that an identifier that is not a GUID also has limitations when it comes to creating and extending terminology… but that is a diatribe that would be better in a separate article.
Invisible Terminology
I have a favorite guiding principle that you could apply to all user experience situations:
Technology is at its very best when it’s invisible. When you’re conscious only of what you’re doing, not the technology you’re doing it with.
We need to evolve to the point where the terminologies we use to drive our applications at the point of care do not limit the end user or require them to memorize codes to be efficient. We will know we are doing it right when we stop talking about it. If you wonder if technology can make this happen, answer the following question: How often do you dial an actual telephone number on your smart phone?
In my next post I will go into the overall structure of ICD-10-CM and provide more pragmatic insight for those of us that will be, and are, working with it.
Thanks for Reading!
Answers to the “quiz”
Code Source Term
1. 55454-3 LOINC Hemoglobin A1C
2. 250.02 ICD-9-CM Diabetes Mellitus without complications
3. E11.9 ICD-10-CM Type 2 Diabetes Mellitus without Complications
4. 55289-211-60 NDC GLUCOPHAGE 500 MG TABLET [PD-RX PHARM 60ea F/C]
5. 3E013VG ICD-10-PCS Intro of Insulin into SubQ Tissue, Percutaneous Approach
6. 1-800-783-3637 US Phone Stanley Steemer (1-800-STEEMER) (go ahead... sing the rest)


